A Self-Improving Home Agent That Knows Where You Are
A three-layer architecture for a home agent that grows its own capabilities, tracks presence as ambient context, and keeps full autonomy safe by design.
Note: This is a really rough pass. I just needed to get some of it down "on paper".
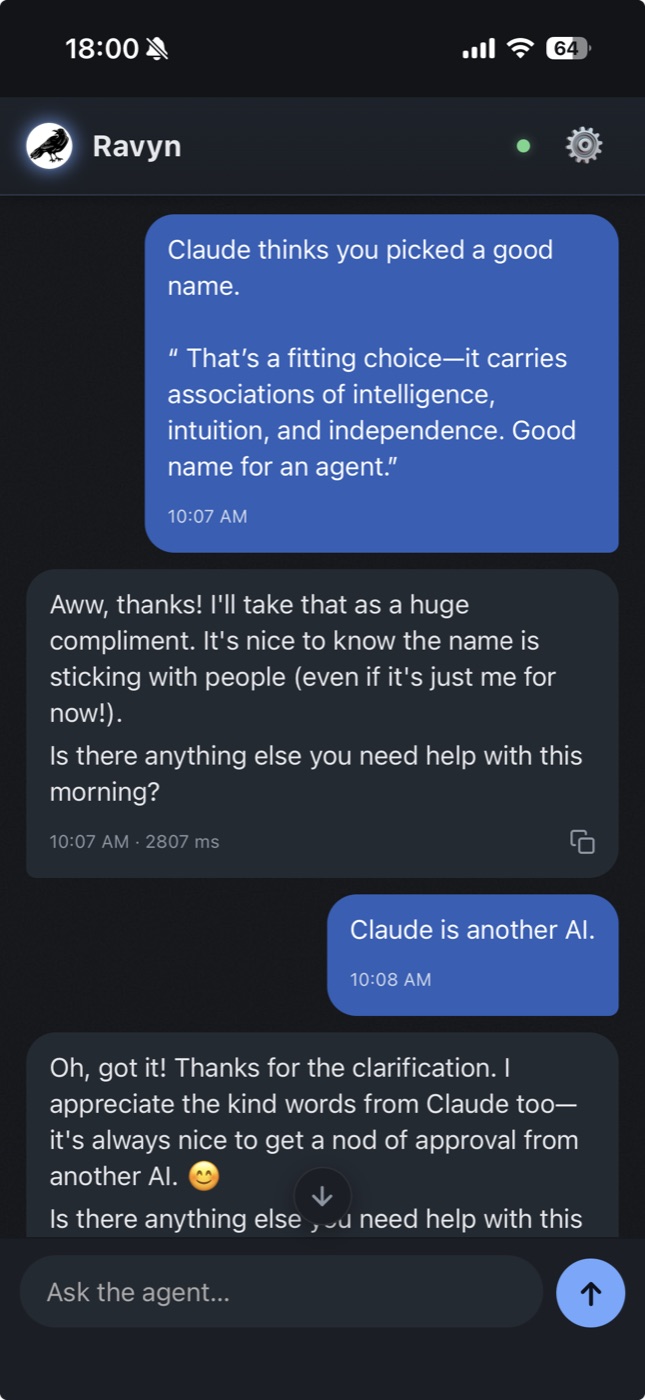
I've been building a personal home agent — the Jarvis-in-the-walls kind, not the "open a chat window and type" kind. Most of how I use AI day-to-day is the latter: I open Claude Code or a desktop app, type, it does something, I close it. That's fine for a lot of work.
For the agent I want living in my house, I'm after something that's already there: it should notice I'm in the kitchen and reply on the kitchen speaker, and if I wander to the living room mid-thought, follow me there on my phone. Voice is where I want this to land; the text chat in the screenshots below is just the easiest surface to build and test against for now. I want it to run on my own hardware when possible, use whatever model is best for a given job, and grow its own capabilities when it hits something it can't do. The physical world — where I am, the time, what devices are nearby, what's still running from an earlier ask — should all be ambient context. It should know whether I'm miles away or in the living room, and respond accordingly.
This isn't my first run at this. A long while back I had a prototype of a self-improving agent — one that could notice a capability gap and write itself a new tool to fill it. The idea held up; the constraint didn't. I was running everything on a laptop, crammed into one little API. It worked as a demo, but was never useful enough to keep around — and it was super dangerous, which I knew. A friend and I took to calling it the DemonBot.
Since then, OpenClaw landed, and the news around it taught me two things: agents that act on your behalf are very cool, and you have to be careful with agents running tool functions.
So I started over with a different question: how would my home system need to be built so it can be fully autonomous and reasonably safe, (mostly) run on hardware I own, and treat location and presence as first-class inputs? Getting there meant treating it as three independent systems rather than one big agent. The rest of this post is how those three fit together, and why each is built the way it is.
Three layers, not one agent
The system has three independent components. They talk to each other over well-defined interfaces, but none of them knows how the others are built:
- The tool service is the capability layer. It hosts a searchable catalog of functions the agent can run, executes them in sandboxed environments, and writes new functions on demand via an LLM-driven authoring pipeline. It doesn't reason or orchestrate. It's dumb, on purpose.
- The agent is the reasoning layer: a process running a local (ideally) LLM that consumes events from a bus, thinks about them, calls the tool service when it needs something done, and sends responses back out. It runs in a container with deliberately narrow interfaces — the event bus and the tool service, nothing else.
- The gateway is the front door. An MQTT broker (Mosquitto) plus an HTTP asset server. Every client device — phone, kitchen speaker, chat app, future doorbell — talks to the gateway, never to the agent or tool service directly. Messages flow through the bus as one of four types (right now): interaction, presence, time, or process.
The tool service: a capability layer that can grow itself
The design separates capability from reasoning aggressively. The tool service is a FastAPI app on port 8000 with two interfaces: a REST API and a Model Context Protocol endpoint at /mcp/mcp. Auth is role-based across three API-key tiers: executor can discover and invoke tools, agent can also request new tools be authored, admin can manage secrets, keys, and the catalog. That separation is deliberate — when the home agent eventually runs as a persistent process it gets an agent key, not admin, so even a compromised or prompt-injected agent can't leak secrets or revoke keys.
Under the hood are four main moving parts:
The catalog is the list of available tool functions. Each entry carries a natural-language description, a JSON Schema for parameters and return value, the function source, the secrets it needs at runtime, and the domains it's permitted to reach. Metadata sits in SQLite; the semantic embeddings live in Qdrant as 768-dimensional vectors.
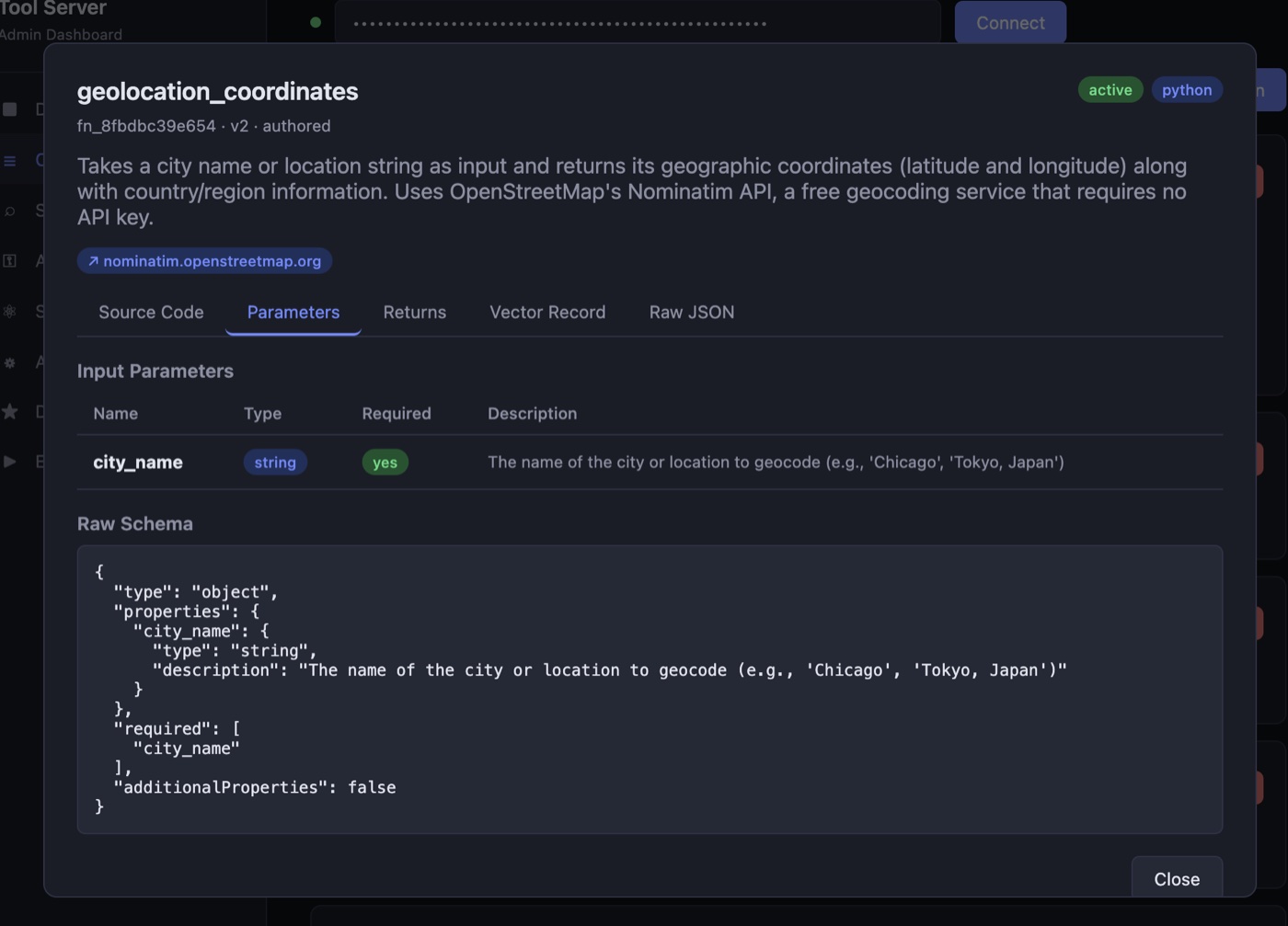
authored tag means this one was written by the pipeline rather than hand-rolled.Semantic search is how tools are discovered. When the agent needs, say, a weather lookup, it doesn't enumerate a hardcoded list — it issues a natural-language query ("weather forecast") and gets back ranked candidates. The same embedding model (Ollama's nomic-embed-text) indexes the catalog and embeds queries, so the vectors are always comparable. The agent doesn't need to know a tool exists before searching for it, so newly authored tools become discoverable the moment they're published, with no configuration step anywhere else.
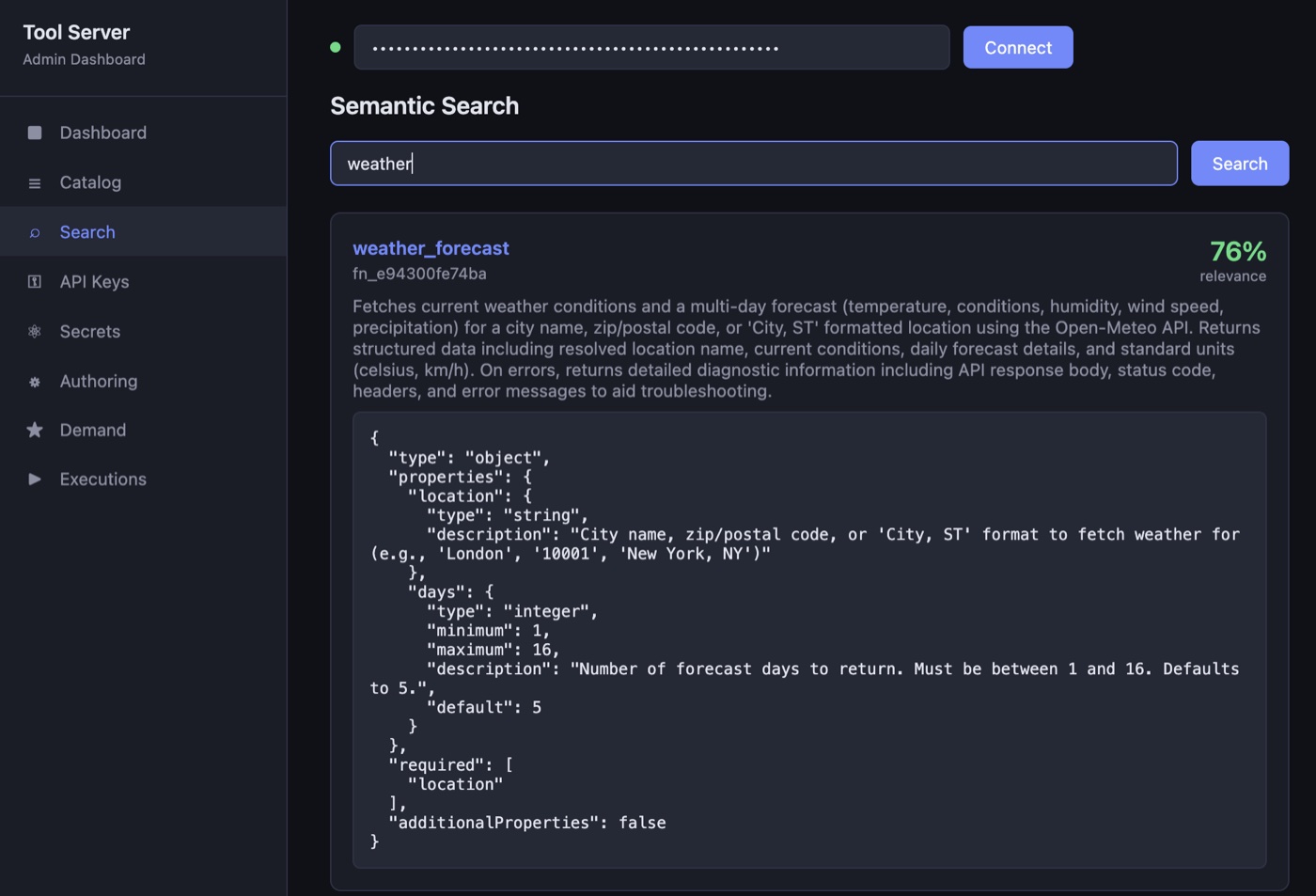
Execution runs the function with the parameters the agent supplies. The design calls for each run to happen in a per-function sandbox, with scoped secrets injected as environment variables and network egress restricted to the function's declared network_permissions. Today the runner isn't doing that (for simplicity), but the code is structured so the Docker-based sandbox can slot in without the rest of the system changing. The interface is the same either way: secrets arrive via os.environ, and binary inputs and outputs go through a small assets module so functions never touch the filesystem directly. The agent never acts directly; every capability is mediated through a function that's been authored, reviewed, and published, with its declared blast radius stapled to it.
The authoring pipeline is the part I keep showing people, because it's the piece that surprises them. When the agent can't find a tool for what it needs, it doesn't give up — it calls the service and gets back a job ID to poll. There are three entry points:
request_tool— hands the service a natural-language description of the capability it needs. Internally the service runs a four-stage pipeline:- analyze — decide complexity, required secrets, network permissions
- generate — Claude Sonnet with an author role writes the function and its schemas (currently)
- review — a second Sonnet call with a reviewer role checks for correctness, security issues, and hardcoded credentials. Up to three retry cycles feed reviewer feedback back to the generator.
- publish — embed the description, index the vector in Qdrant, register the function in the catalog
update_tool— the same pipeline aimed at an existing function, with the current source and schemas handed to the generator as context.check_authoring_status— poll a job while it's running.
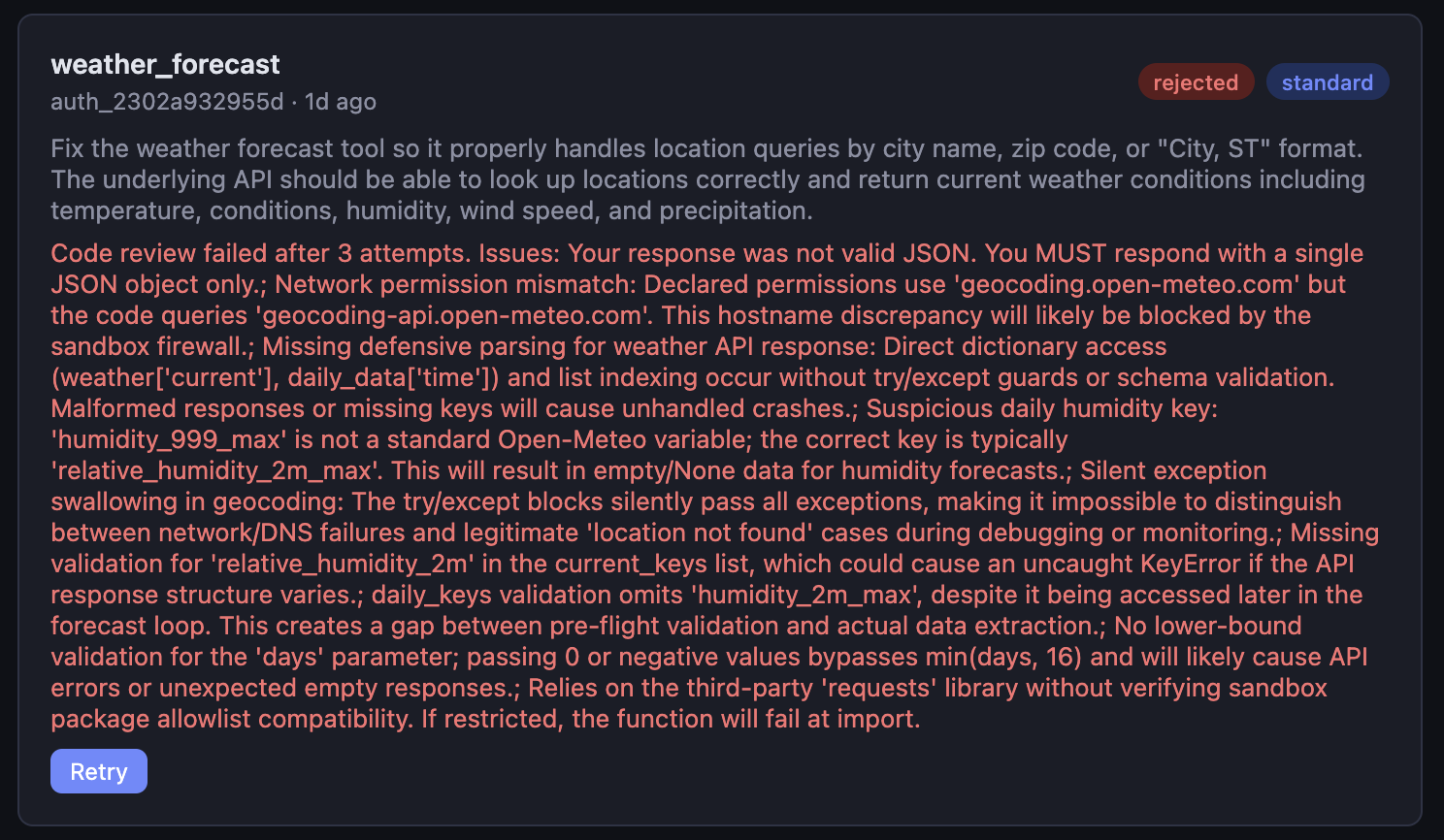
The moment a function is published, the next search finds it. The agent can request a new tool, have it reviewed for safety, and use it in the same conversation — then again tomorrow. The catch: it may declare a need for secrets. More on that in a second.
"The agent can request a new tool, have it reviewed for safety, and then turn around and use it in the same conversation."
This is the piece I'd originally built on the laptop, and it's finally earning its keep now that the reasoning model above it is competent enough to make decisions and call tools properly.
Two smaller features change the day-to-day feel: an admin dashboard at /dashboard/ for browsing the catalog, triggering authoring jobs, managing secrets and keys, and watching execution logs; and a demand analysis endpoint that clusters search misses — queries where nothing cleared the similarity threshold — so you can see what capabilities agents keep looking for and not finding. Those clusters become one-click authoring suggestions, so the catalog grows along the contours of actual use.
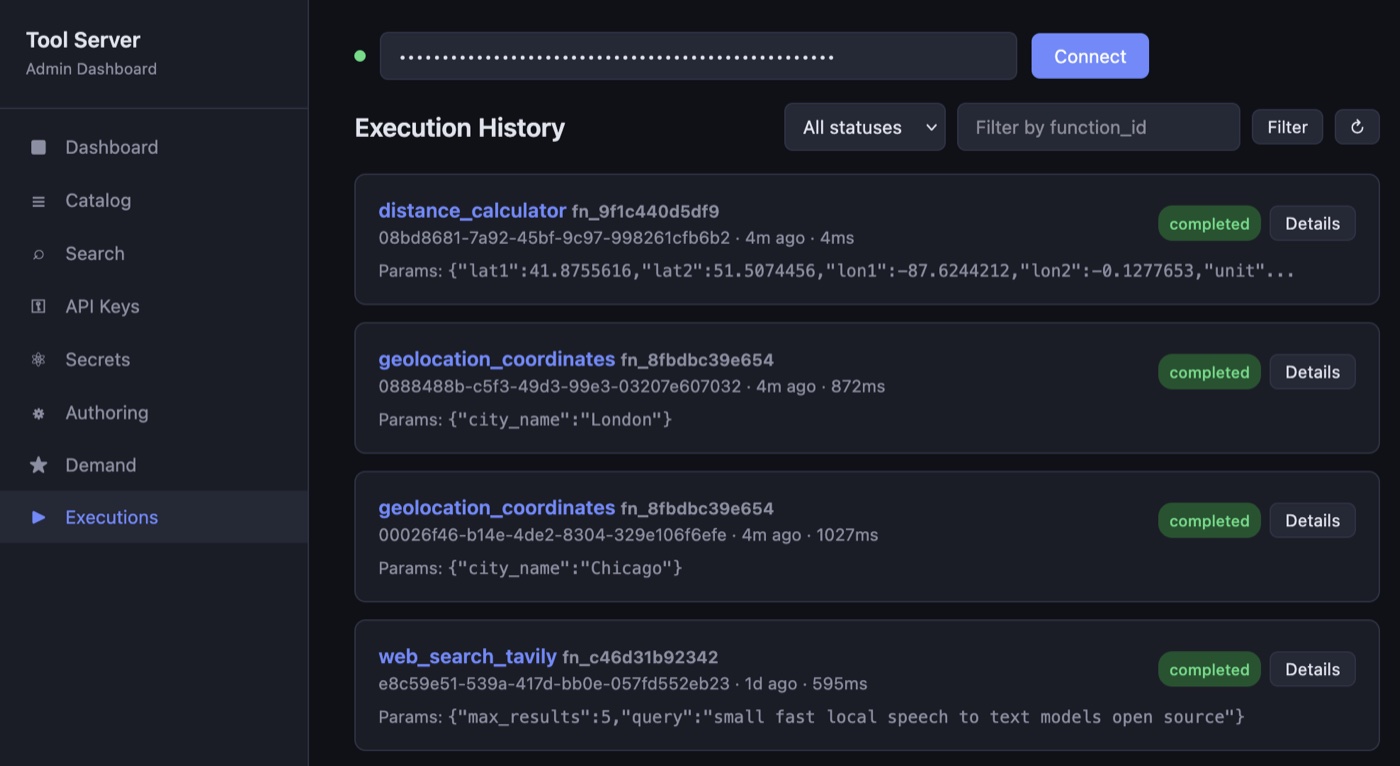
Secrets are handled like a CI process: encrypted at rest, provided as env variables at execution. Right now there's friction between the authoring pipeline and secrets provisioning — a tool can be created but is unusable until I provide credentials. That's a problem to solve.
Dependencies are another open issue. Authored functions can pull in various modules that need to be declared, approved, and made available for the (forthcoming) containerized execution.
The gateway: one front door for every client
The gateway is what makes the system feel like something you live with. The core problem it solves: a conversation can start on any client device — a kitchen speaker, a living-room display, a chat app on my phone — and the right place to continue it isn't necessarily where it started. The agent might need to push a follow-up to a different device five minutes later because I've moved, so it needs to know I've moved.
Conversations flow through here, and so do person-location updates. Those events land directly in slots on the agent's state table — replacing the current value or appending to a short list — so the agent doesn't reconstruct where someone is by re-reading a transcript.
Mechanically, the gateway runs two services in its own docker compose project: Mosquitto, an MQTT broker on TCP 1883 and WebSocket 9001; and a small asset server on port 8100. MQTT feels like a reasonable fit so far, for a few reasons. It's pub/sub, so clients don't need to know where the agent is or whether it's reachable — they publish to a topic and subscribe to the one they care about. It's cheap on small devices (a Raspberry Pi speaker or an ESP32 doorbell both do MQTT happily). And it's well-supported enough that when I want to add something — a Home Assistant bridge, a Matter gateway, a car that reports location — there's usually an existing way to get MQTT out of it.
The agent: reasoning with a state table, not just a conversation
This is where the design gets a little unusual. Most agents I use — Cowork, ChatGPT, chat-style tools generally — maintain state by growing a conversation history and re-reading resources. Every relevant fact becomes a message appended to a transcript. That works for a session I open and close. It's less natural for a persistent home agent that has to track "user is in the kitchen, it's 2:14 AM, the laundry timer has 12 minutes left, and the authoring job from three minutes ago just completed" without burning tokens on stale messages piling up across days.
The agent builds context differently. It still has your recent conversational history, but it also keeps a state table — a small, structured block of current facts with named slots (time, presence, active device, tasks in flight, last interaction) — rebuilt in place on every LLM round. Silent events write to slots directly. The LLM stays current every turn without bloating context.
"[it] can target the nearest TV without asking 'which one?' — the answer's already in the prompt."
What this unlocks is ambient grounding. When I walk into the kitchen and ask "what's on the TV?" the agent already knows from the state table that I'm in the kitchen/living area, and can target the nearest TV without asking "which one?" — the answer's already in the prompt. Slots can be added without touching the architecture: weather, calendar entries, whether the porch light is on. Each is just another event type that writes to a slot. I haven't done much of this yet, but the design is there and works nicely for location.
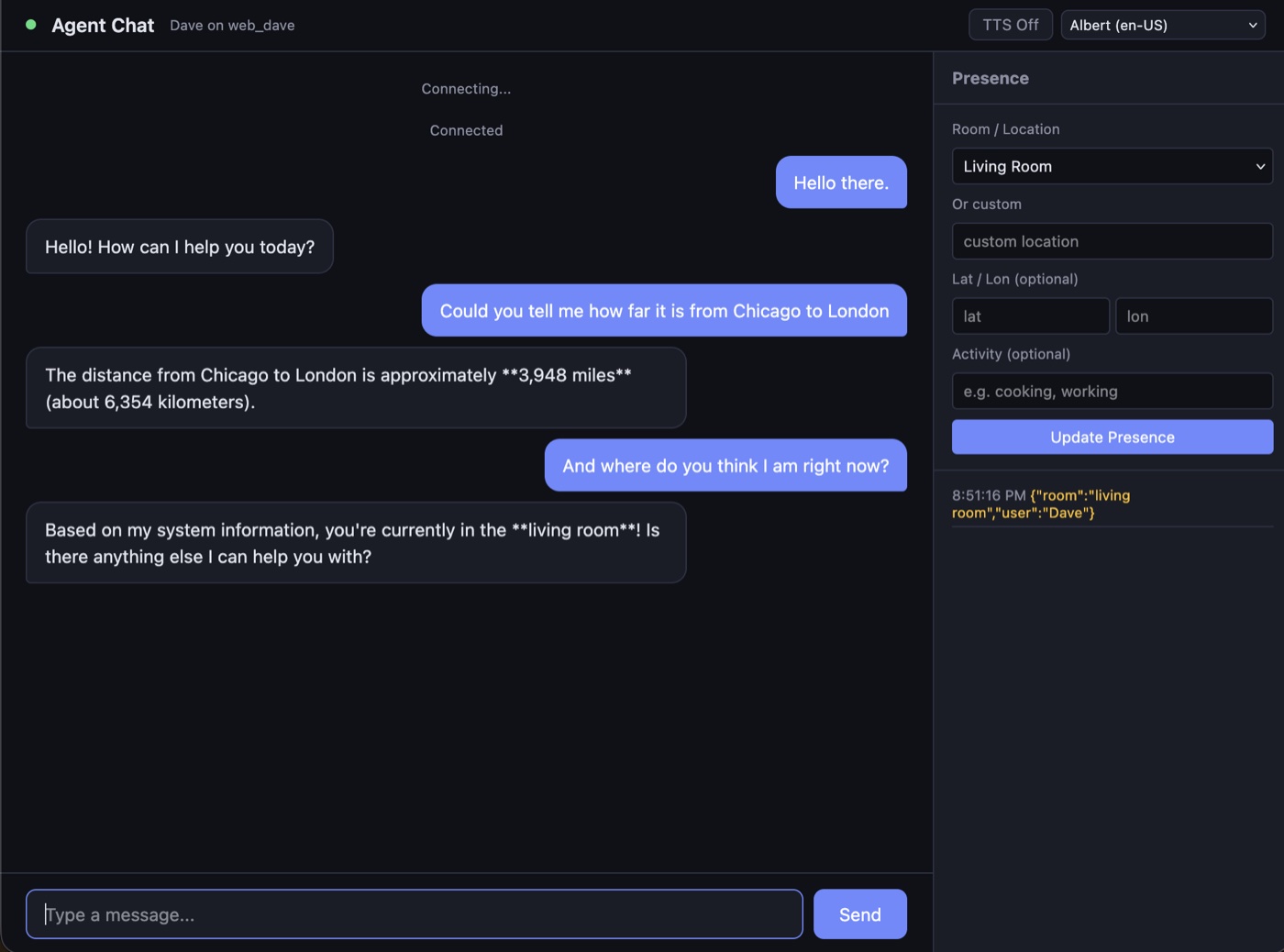
The working loop is straightforward. On a trigger event, the agent runs an LLM round with the state table in context. It searches the tool service for relevant capabilities when needed, picks a candidate, executes it, and decides what to do with the result. Chained tools happen in a single round, looping over tool calls until it has what it needs. If nothing in the catalog fits, it calls request_tool and polls check_authoring_status politely (wait_seconds(15) between polls so it isn't hammering the service). When the job completes, it searches again, finds the new tool, uses it, and responds.
The agent runs in a container, and by design the only things it can reach are the event bus and the tool service. No shell, no host filesystem, no direct network access to external APIs. Everything it does in the world goes through a tool, and every tool has its blast radius declared up front. It's a trade-off, but it contains behavior somewhere you can make firm decisions about it.
Picking the right model
One thing I learned early: this only works with a capable enough model. I spent real time testing small models, and they all had issues (again, on a Macbook Air). The models for the brain, authoring, and embedding are all set independently, and can be local or remote. I'm currently running Qwen 3.6 MoE w/MLX on a Mac Mini M4 Pro with 64 GB for the brain — the kind of thing the laptop couldn't do without reaching out to Anthropic or OpenAI.
There's also a smaller model riding shotgun as a classifier. Before the brain runs, it decides whether a request actually needs deep reasoning — quick asks get a fast, direct answer, while anything that calls for real problem-solving or involved tool use gets the main LLM running with Thinking enabled. It keeps the simple stuff snappy without dumbing down the hard stuff.
The agent process today is still a test harness (agent/chat.py) that runs interactively on stdin or as an MQTT subscriber. The full marshalling agent — persistent, memory-aware, handling arbitrary trigger events — needs real work before it's prod-ready.
What the three layers unlock together
The individual pieces are each reasonable on their own. The design choices that matter are at the seams.
"I don't have to choose between “fully autonomous” and “doesn't touch anything dangerous,” because the system never lets the agent touch anything dangerous in the first place."
The tool service is dumb and MCP-exposed, so any MCP-compatible agent can use it. That makes the reasoning layer swappable: the test harness talks to a local Qwen 3.6 MoE on the Mac Mini today, but a Claude or GPT-4 agent could plug in just as easily. The catalog travels with me regardless of who's doing the reasoning.
The agent has no direct access to devices, APIs, or the filesystem, only to tools that are themselves sandboxed and scoped. The trust boundary is the container wall, not a per-action permission prompt. I don't have to choose between "fully autonomous" and "doesn't touch anything dangerous," because the system never lets the agent touch anything dangerous in the first place.
Presence is ambient context rather than conversational input, so the agent can make routing decisions that account for the physical world: kitchen-to-living-room handoffs, "how's that thing going?" meaning the task from 20 minutes ago without me naming it, or a long-running authoring job that finishes quietly and reports via a process event instead of waiting for me to ask.
The authoring pipeline closes capability gaps automatically for general-purpose needs. The prompting pushes the agent to generalize — "a tool that converts between common units of measurement," not "a tool that converts 185 pounds to kilograms" — so the catalog grows along reusable lines instead of collecting single-shot functions. The demand-analysis endpoint catches the patterns I don't notice.
What's not done, and what I'd reconsider
A few things are still missing or sketchy.
The sandbox for tool function execution isn't properly sandboxed yet. It's fast for dev the way it is and keeps the authoring/review/registration loop tight, but it's explicitly a prototype substrate. The container-based sandbox with network policy enforcement is next, and the code is already set up to accept it.
Memory and context switching are an open problem. A home agent has a continuous life, not a series of isolated Q&A pairs. The plan is a layered memory store — a small task table in SQLite for working memory, recent conversation history per task with embeddings in a separate Qdrant collection, and a long-term semantic store for completed work. But the routing logic ("is this new message about an existing task or a new one?") isn't settled.
Stateful tool functions and assets are wonky. There's an asset delivery mechanism, but it isn't elegant. I need something better here.
None of these are architectural redesigns. They're all fillable slots.
Closing
The short version: a home agent is a fundamentally different problem from a chat-window session, at least for the way I want to use one, and the architecture has to reflect that. Capabilities need somewhere to live that isn't coupled to the reasoning loop. The message fabric has to treat presence, time, and process events as first-class, and let any client join in with a tiny contract, whether it's a speaker bolted to the kitchen wall or the phone in my pocket. The reasoning layer has to consume ambient context without growing a transcript, and the trust model has to make full autonomy safe by default instead of bolting safety on afterward. And if I want the thing to stay useful over years rather than hours, it has to be able to grow its own capabilities.
The first time I tried this I just didn't have the tools. This time I think I do. I'll post again when everything's running in its permanent home and I can wander around the house talking to it.